Learning Module
Learning modules are the core modeling system of Monty. They are responsible for learning models from the incoming data (either from a sensor module or another learning module). Their input and output formats are features at a pose. Using the displacement between two consecutive poses, they can learn object models of features relative to each other and recognize objects that they already know, independent of where they are in the world. How exactly this happens is up to each learning module and we have several different implementations for this.
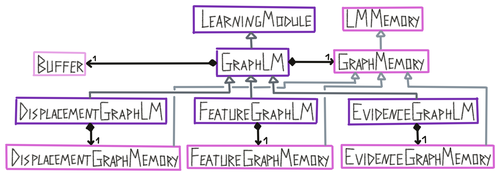
Generally, each learning module contains a buffer, which functions as a short term memory, and some form of long term memory that stores models of objects. Both can then be used to generate hypotheses about what is currently being sensed, update, and communicate these hypotheses. If certainty about a sensed object is reached, information from the buffer can be processed and integrated into the long term memory. Finally, each learning module can also receive and send target states, using a goal generator, to guide the exploration of the environment.
Specific Implementations
The details of specific graph LM implementations, approaches, results, and problems are too much for this overview document. They are written out in a separate document here. Other approaches that we tried but discontinued can be found in our monty_lab repository.
| List of all learning module classes | Description |
|---|---|
| LearningModule | Abstract learning module class. |
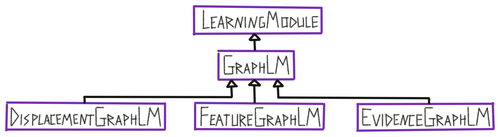
| GraphLM | Learning module that contains a graph memory class and a buffer class. It also has properties for logging the target and detected object and pose. It contains functions for calculating displacements, updating the graph memory and logging. Class is not used on its own but is super-class of DisplacementGraphLM, FeatureGraphLM, and EvidenceGraphLM. |
| DisplacementGraphLM | Learning module that uses the displacements stored in graph models to recognize objects. |
| FeatureGraphLM | Learning module that uses the locations stored in graph models to recognize objects. |
| EvidenceGraphLM | Learning module that uses the locations stored in graph models to recognize objects and keeps a continuous evidence count for all its hypotheses. |
Since we currently focus on learning modules that use 3D object graphs, we will explain the workings of Monty on this example here in some more detail. Using explicit 3D graphs makes visualization more intuitive and makes the system more transparent and easier to debug. This does not mean that we think the brain stores explicit graphs! We are using graphs while we are nailing down the framework and the Cortical Messaging Protocol. This is just one possible embodiment of a learning module. How we represent graphs inside a learning module has no effect on the other components of Monty or the general principles of Monty. Explicit graphs are the most concrete type of model that uses reference frames and helped us think through a lot of problems related to that so far. In the future, we may move away from explicit graphs towards something more like HTM in combination with grid-cell like mechanisms but for now, they can help us understand the problems and possible solutions better.
The evidence-based LM is currently the default LM used for benchmarking the Monty system. We will therefore go into a bit more detail on this in Evidence Based Learning Module. The other approaches listed above are not under active development. DisplacementGraphLM and FeatureGraphLM are maintained but do not support hierarchy.
Comparison between 3 Graph Learning Modules
There are currently three flavors of graph matching implemented: Matching using displacements, matching using features at locations, and matching using features at locations but with continuous evidence values for each hypothesis instead of a binary decision. They all have strengths and weaknesses but are generally successive improvements. They were introduced sequentially as listed above and each iteration was designed to solve problems of the previous one. Currently, we are using the evidence-based approach for all of our benchmark experiments.
Displacement matching has the advantage that it can easily deal with translated, rotated and scaled objects and recognize them without additional computations for reference frame transforms. If we represent the displacement in a rotation-invariant way (for example as point pair features) the recognition performance is not influenced by the rotation of the object. For scale, we can simply use a scaling factor for the length of the displacements which we can calculate from the difference in length between the first sensed displacement and stored displacements of initial hypotheses (assuming we sample a displacement that is stored in the graph, which is a strong assumption). It is the only LM that can deal with scale at the moment. The major downside of this approach is that it only works if we sample the same displacements that are stored in the graph model of the object while the number of possible displacements grows explosively with the size of the graph.
Feature matching addresses this sampling issue of displacement matching by instead matching features at nearby locations in the learned model. The problem with this approach is that locations are not invariant to the rotation of the reference frame of the model. We, therefore, have to cycle through different rotations during matching and apply them to the displacement that is used to query the model. This however is more computationally expensive.
Both previous approaches use a binary approach to eliminate possible objects and poses. This means that if we get one inconsistent observation, the hypothesis is permanently eliminated from the set of possible matches. The evidence-based LM deals with this issue by assigning a continuous evidence value to each hypothesis which is updated with every observation. This makes the LM much more robust to noise and new sampling. Since the set of hypotheses retains the same size over the entire episode we can also use more efficient matrix multiplications and speed up the recognition procedure. The evidence count also allows us to have a most likely hypothesis at every step, even if we have not converged to a final classification yet. This is useful for further hierarchical processing and action selection at every step.
Overall, matching with displacements can deal well with rotated and scaled objects but fails when sampling new displacements on the object. Feature matching does not have this sampling issue but instead requires a more tedious search through possible rotations and scale is an open problem. Evidence matching uses the mechanisms of feature matching but makes them more robust by using continuous evidence counts and updating the evidence with efficient matrix multiplications.
Help Us Make This Page Better
All our docs are open-source. If something is wrong or unclear, submit a PR to fix it!
Updated about 1 month ago