Cortical Messaging Protocol
We use a common messaging protocol that all components (LMs, SMs, and motor systems) adhere to. This makes it possible for all components to communicate with each other and to combine them arbitrarily. The CMP defines what information the outputs of SMs and LMs need to contain.
In short, a CMP-compliant output contains features at a pose. The pose contains a location in 3D space (naturally including 1D or 2D space) and represents where the sensed features are relative to the body, or another common reference point such as a landmark in the environment. The pose also includes information about the feature's 3D rotation. Additionally, the output can contain features that are independent of the object's pose such as color, texture, temperature (from the SM), or object ID (from the LM).
Besides features and their poses, the standard message packages also include information about the sender's ID (e.g., the particular sensor module) and a confidence rating.
The inputs and outputs of the system (raw sensory input to the SM and motor command outputs from the policy) can have any format and do not adhere to any messaging protocol. They are specific to the agents' sensors and actuators and represent the systems interface with the environment.
The lateral votes between learning modules communicate unions of possible poses and objects. They do not contain any information about "features" from the perspective of that learning module's level of hierarchical processing. In other words, while an LM's object ID might be a feature at higher levels of processing, lateral votes do not send information about the features which that learning module itself has received. We further note that the vote output from one LM can also include multiple CMP message packages, representing multiple possible hypotheses.
At no point do we communicate structural model information between learning modules. What happens within a learning module does not get communicated to any other modules and we never share the models stored in an LMs memory.
Communication between components (SMs, LMs, and motor systems) happens in a common reference frame (e.g., relative to the body). This makes it possible for all components to meaningfully interpret the pose information they receive. Internally, LMs then calculate displacements between consecutive poses and map them into the model's reference frame. This makes it possible to detect objects independently of their pose.
The common reference frame also supports voting operations accounting for the relative displacement of sensors, and therefore LM models. For example, when two fingers touch a coffee mug in two different parts, one might sense the rim, while the other senses the handle. As such, "coffee mug" will be in both of their working hypotheses about the current object. When voting however, they do not simply communicate "coffee mug", but also where on the coffee mug other learning modules should be sensing it, according to their relative displacements. As a result, voting is not simply a "bag-of-features" operation, but is dependent on the relative arrangement of features in the world.
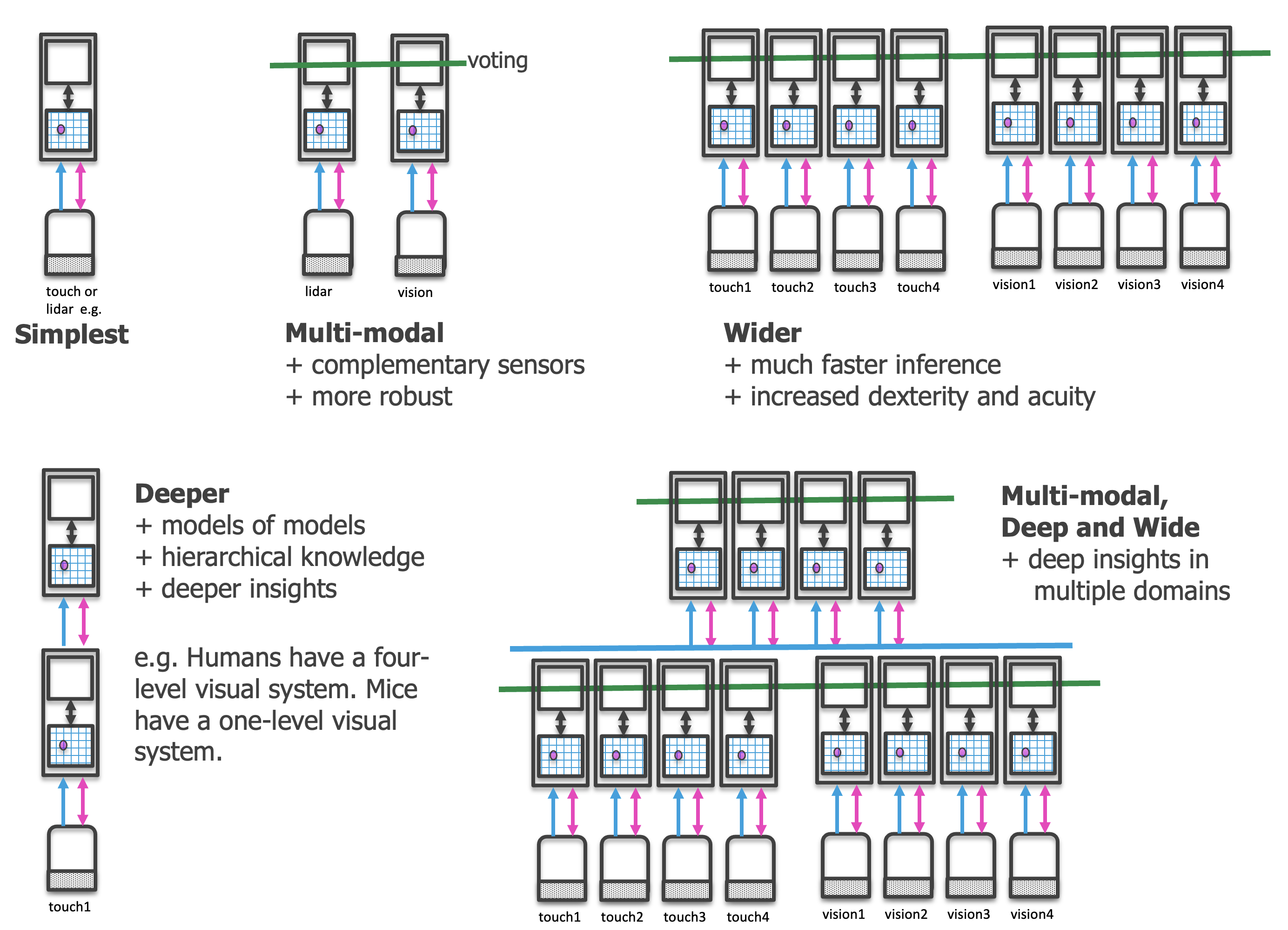
See our implementation documentation for details on how we implement the CMP in Monty.
Help Us Make This Page Better
All our docs are open-source. If something is wrong or unclear, submit a PR to fix it!
Updated 5 months ago