Benchmark Experiments
Performance of current implementation on our benchmark test suite.
General Notes
These benchmark experiments are not common benchmarks from the AI field. There are a set of experiments we have defined for ourselves to track our research progress. They specifically evaluate capabilities that we have added or plan to add to Monty.
You can find Monty experiment configs for all the following experiments in the benchmarks folder. Note that the experiment parameters are not overly optimized for accuracy. The parameters used here aim to strike a good balance between speed and accuracy to allow our researchers to iterate quickly and evaluate algorithm changes regularly. If a particular use case requires higher accuracy or faster learning or inference, this can be achieved by adjusting learning module parameters.
The runtimes reported in the tables below reflect the total experiment runtime, which includes overhead such as environment setup (e.g., Habitat initialization), logging, and telemetry. The isolated Monty runtime (i.e., the time spent on learning or inference) is typically less than the reported values. In Wandb logs, this corresponds to the column labeled RUNTIME.
If you want to evaluate Monty on external benchmarks, please have a look at our application criteria and challenging preconceptions pages first. Particularly, note that Monty is a sensorimotor system made to efficiently learn and infer by interacting with an environment. It is not designed for large, static datasets.
Object and Pose Recognition on the YCB Dataset
What Do We Test?
We split up the experiments into a short benchmark test suite and a long one. The short suite tests performance on a subset of 10 out of the 77 YCB objects which allows us to assess performance under different conditions more quickly. Unless otherwise indicated, the 10 objects are chosen to be distinct in morphology and models are learned using the surface agent, which follows the object surface much like a finger.
When building the graph we add a new point if it differs in location by more than 1cm from other points already learned, or its features are different from physically nearby learned points (a difference of 0.1 for hue and 1 for log curvature). Experiments using these models have 10distobj in their name.

To be able to test the ability to distinguish similar objects (for example by using more sophisticated policies) we also have a test set of 10 similar objects (shown below) learned in the same way. Experiments using these models have 10simobj in their name.

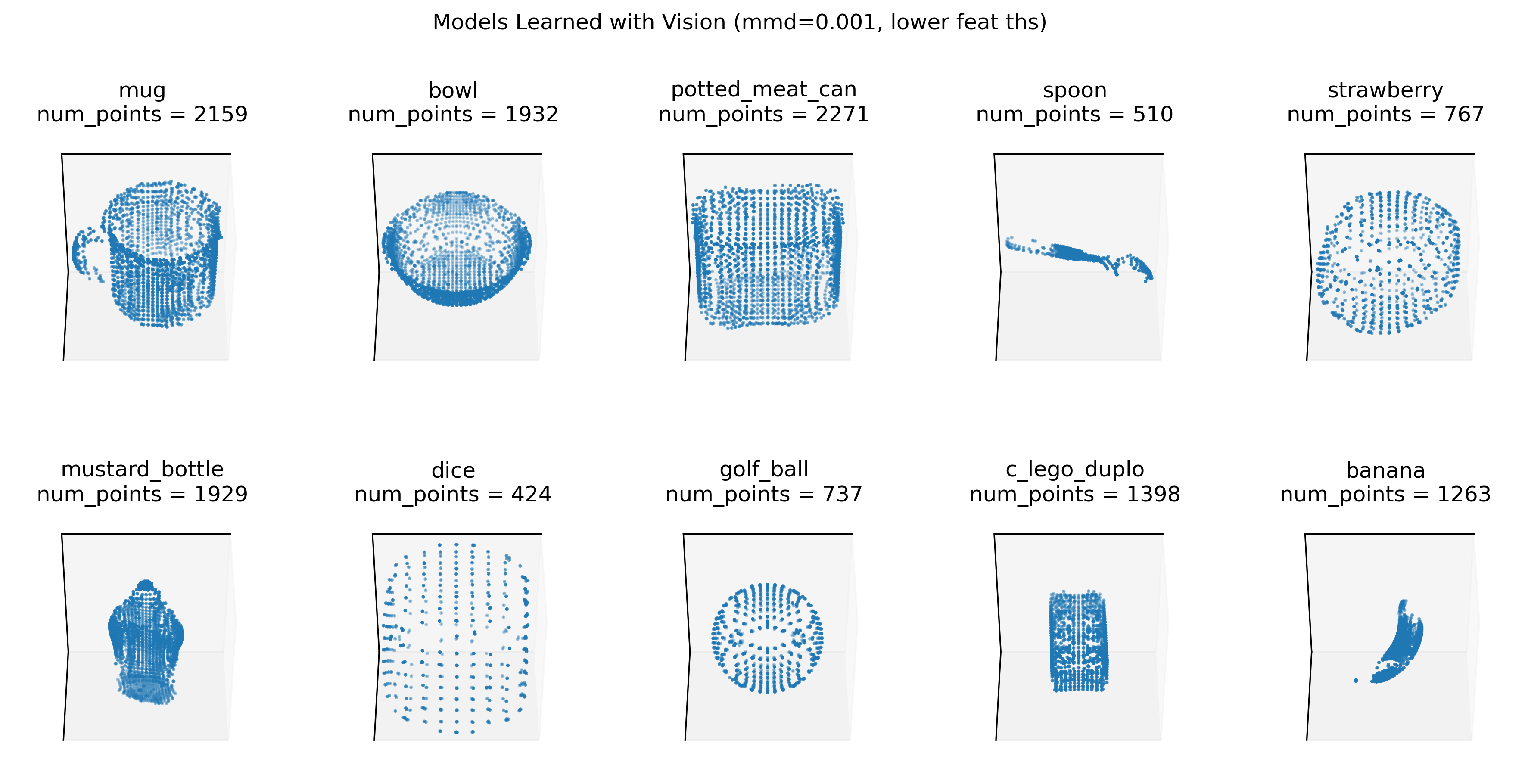
For experiments with multiple sensors and learning modules we currently only have a setup with the distant agent so we also have to train the models with the distant agent. These models have less even coverage of points since we just see the objects from several fixed viewpoints and can't move as freely around the object as we can with the surface agent. This is why these models have a few missing areas where parts of the object were never visible during training. In the 5LM experiments, each LM has learned slightly different models, depending on their sensor parameters. The image below shows the models learned in one LM. Results with one LM for comparability are given in the experiment marked with dist_on_distm (i.e., distant agent evaluated on distant-agent trained models).
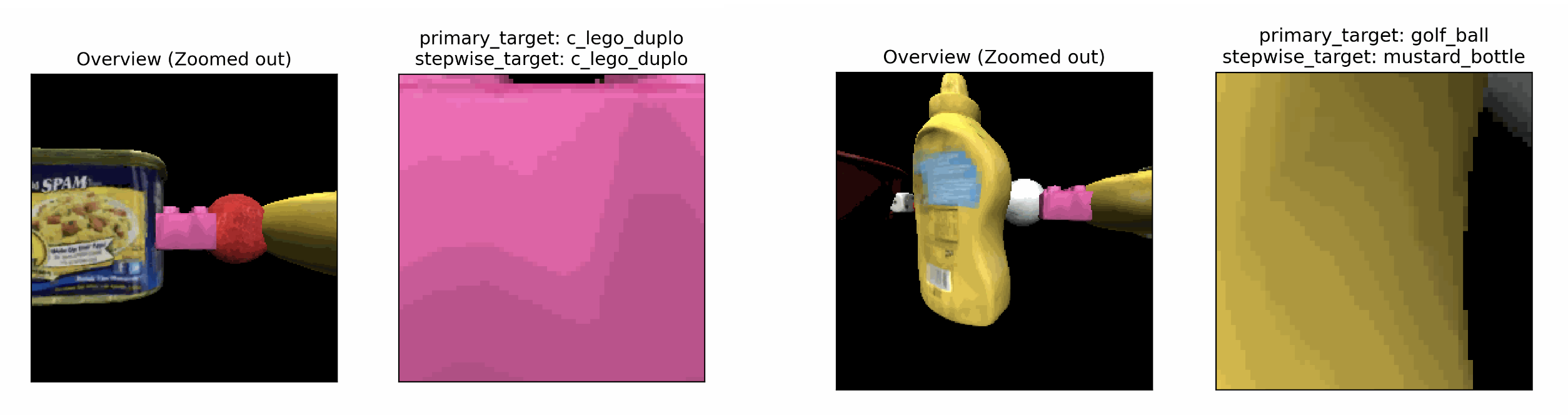
Configs with multi in the name have additional distractor objects, in addition to the primary target object. These experiments are designed to evaluate the model's ability to stay on an object until it is recognized. As a result, these are currently setup so that the agent should always begin on a "primary" target object, and recognition of this object is the primary metric that we evaluate. In addition however, there is a "step-wise" target, which is whatever object an LM's sensor is currently viewing; the ultimate MLH or converged ID of an LM is therefore also compared to the step-wise target that the LM was observing at the time. To make recognition of the primary target relatively challenging, distractor objects are added as close as possible along the horizontal axis, while ensuring that i) the objects do not clip into each other, and ii) that an initial view of the primary target is achieved at the start of the episode. Note these experiments cannot currently be run with multi-processing (the -m flag), as the Object Initializer classes need to be updated. Example multi-object environments are shown below.
Configs with _dist_agent in the name use the distant agent for inference (by default they still use the models learned with the surface agent). This means that the sensor is fixed in one location and can only tilt up, down, left, and right following a random walk. When using the model-based hypothesis-testing policy, the agent can also "jump" to new locations in space. Configs with surf_agent in the name use the surface agent for inference which can freely move around the entire object. Both the surface and the distant agent can execute model-based actions using the hypothesis testing policy. For more details, see our documentation on policies.
Configs with base in their name test each object in the 14 orientations in which they were learned. No noise is added to the sensor.
Configs with randrot in their name test each object in 10 random, new rotations (different rotations for each object).
Configs with noise in their name test with noisy sensor modules where we add Gaussian noise to the sensed locations (0.002), surface normals (2), curvature directions (2), log curvatures (0.1), pose_fully_defined (0.01), and hue (0.1). Numbers in brackets are the standard deviations used for sampling the noisy observations. Note that the learned models were acquired without sensor noise. The image below should visualize how much location noise we get during inference but the LM still contains the noiseless models shown above.

Configs with rawnoise in the name test with noisy raw sensor input where Gaussian noise is applied directly to the depth image which is used for location, surface normal, and curvature estimation. Here we use a standard deviation of 0.001. This allows us to test the noise robustness of the sensor module compared to testing the noise robustness of the learning module in the noise experiments.
Note that all benchmark experiments were performed with the total least-squares regression implementation for computing the surface normals, and the distance-weighted quadratic regression for the principal curvatures (with their default parameters).
Shorter Experiments with 10 Objects
The following results are obtained from experiments using the 10-object subsets of the YCB dataset described above. base configs test with all 14 known rotations (10 objects 14 rotations each = 140 episodes), and randrot configs test with 10 random rotations (10 objects 10 rotation each = 100 episodes). All experiments were run on 16 CPUs with parallelization except for base_10multi_distinctobj_dist_agent; this experiment must be run without parallelization.
Results
| Experiment | Correct (%) | Used MLH (%) | Num Match Steps | Rotation Error (degrees) | Run Time (mins) | Episode Run Time (s) |
|---|---|---|---|---|---|---|
| base_config_10distinctobj_dist_agent | 100.00 | 2.86 | 34 | 8.64 | 3 | 7 |
| base_config_10distinctobj_surf_agent | 100.00 | 0.00 | 28 | 3.87 | 3 | 11 |
| randrot_noise_10distinctobj_dist_agent | 100.00 | 2.00 | 35 | 13.23 | 3 | 14 |
| randrot_noise_10distinctobj_dist_on_distm | 100.00 | 3.00 | 31 | 15.42 | 3 | 13 |
| randrot_noise_10distinctobj_surf_agent | 100.00 | 0.00 | 29 | 10.37 | 4 | 27 |
| randrot_10distinctobj_surf_agent | 100.00 | 0.00 | 29 | 5.16 | 2 | 11 |
| randrot_noise_10distinctobj_5lms_dist_agent | 100.00 | 1.00 | 50 | 56.65 | 6 | 37 |
| base_10simobj_surf_agent | 98.57 | 4.29 | 53 | 3.53 | 4 | 18 |
| randrot_noise_10simobj_dist_agent | 88.00 | 32.00 | 202 | 30.3 | 10 | 75 |
| randrot_noise_10simobj_surf_agent | 97.00 | 28.00 | 157 | 18.01 | 18 | 144 |
| randomrot_rawnoise_10distinctobj_surf_agent | 67.00 | 75.00 | 13 | 105.66 | 5 | 7 |
| base_10multi_distinctobj_dist_agent | 47.14 | 4.29 | 33 | 18.42 | 36 | 2 |
Longer Experiments With all 77 YCB Objects
The following results are obtained from experiments on the entire YCB dataset (77 objects). Since this means having 77 instead of 10 objects in memory, having to disambiguate between them, and running 77 episodes instead of 10 per epoch, these runs take significantly longer. Due to that we only test 3 known rotations ([0, 0, 0], [0, 90, 0], [0, 180, 0]) for the base configs and 3 random rotations for the randrot configs. The 5LM experiment is currently just run with 1 epoch (1 random rotation per object) but might be extended to 3. The 5LM experiment is run on 48 CPUs instead of 16.

Results
| Experiment | Correct (%) | Used MLH (%) | Num Match Steps | Rotation Error (degrees) | Run Time (mins) | Episode Run Time (s) |
|---|---|---|---|---|---|---|
| base_77obj_dist_agent | 93.94 | 10.39 | 78 | 11.10 | 16 | 41 |
| base_77obj_surf_agent | 100.00 | 4.33 | 45 | 4.14 | 13 | 31 |
| randrot_noise_77obj_dist_agent | 88.74 | 17.75 | 120 | 33.03 | 26 | 75 |
| randrot_noise_77obj_surf_agent | 99.57 | 20.35 | 109 | 23.73 | 37 | 121 |
| randrot_noise_77obj_5lms_dist_agent | 96.10 | 1.3 | 68 | 57.04 | 16 | 144 |
Explanation of Some of the Results
-
Why does the distant agent do worse than the surface agent?
The distant agent has limited capabilities to move along the object. In particular, the distant agent currently uses an almost random policy which is not as efficient and informative as the surface agent which follows the principal curvatures of the object. Note however that both the distant and surface agent can now move around the object using the hypothesis-testing action policy, and so the difference in performance between the two is not as great as it previously was. -
Why is the distant agent on the distant agent models worse than on the surface agent model?
As you can see in the figure above, the models learned with distant agent have several blind spots and unevenly sampled areas. When we test random rotations we may see the object from views that are underrepresented in the object model. If we use a 10% threshold instead of 20% we can actually get a little better performance with the distant agent since we allow it to converge faster. This may be because it gets less time to move into badly represented areas and because it reaches the time-out condition less often. -
Why is the accuracy on distinct objects higher than on similar objects?
Since we need to be able to deal with noise, it can happen that objects that are similar to each other get confused. In particular, objects that only differ in some specific locations (like the fork and the spoon) can be difficult to distinguish if the policy doesn't efficiently move to the distinguishable features and if there is noise. -
Why is raw sensor noise so much worse than the standard noise condition?
This is not related to the capabilities of the learning module but to the sensor module. Currently, our surface normal and principal curvature estimates are not implemented to be very robust to sensor noise such that noise in the depth image can distort the surface normal by more than 70 degrees. We don't want our learning module to be robust to this much noise in the surface normals but instead want the sensor module to communicate better features. We already added some improvements on our surface normal estimates which helped a lot on the raw noise experiment. -
Why do the distant agent experiments take longer and have more episodes where the most likely hypothesis is used?
Since the distant agent policy is less efficient in how it explores a given view (random walk of tilting the camera), we take more steps to converge with the distant agent or sometimes do not resolve the object at all (this is when we reach a time-out and use the MLH). If we have to take more steps for each episode, the runtime also increases. -
Why is the run time for 77 objects longer than for 10?
For one, we run more episodes per epoch (77 instead of 10) so each epoch will take longer. However, in the current benchmark, we test with fewer rotations (only 3 epochs instead of 14 or 10 epochs in the shorter experiments). Therefore the main factor here is that the number of evidence updates we need to perform at each step scales linearly with the number of objects an LM has in its memory (going down over time as we remove objects from our hypothesis space). Additionally, we need to take more steps to distinguish 77 objects than to distinguish 10 (especially if the 10 objects are distinct).
Unsupervised Learning
In general, we want to be able to dynamically learn and infer instead of having a clear-cut separation between supervised pre-training followed by inference. We also want to be able to learn unsupervised. This is tested in the following experiment using the surface agent. We test the same 10 objects set as above with 10 fixed rotations. In the first epoch, each object should be recognized as new (no_match) leading to the creation of a new graph. The following episodes should correctly recognize the object and add new points to the existing graphs. Since we do not provide labels it can happen that one object is recognized as another one and then their graphs are merged. This can especially happen with similar objects but ideally, their graphs are still aligned well because of the pose recognition. It can also happen that one object is represented using multiple graphs if it was not recognized. Those scenarios are tracked with the mean_objects_per_graph and mean_graphs_per_object statistics.
An object is classified as detected correctly if the detected object ID is in the list of objects used for building the graph. This means, if a model was built from multiple objects, there are multiple correct classifications for this model. For example, if we learned a graph from a tomato can and later merge points from a peach can into the same graph, then this graph would be the correct label for tomato and peach cans in the future. This is also why the experiment with similar objects reaches a higher accuracy after the first epoch. Since in the first epoch we build fewer graphs than we saw objects (representing similar objects in the same model) it makes it easier later to recognize these combined models since, for this accuracy measure, we do not need to distinguish the similar objects anymore if they are represented in the same graph. In the most extreme case, if during the first epoch, all objects were merged into a single graph, then the following epochs would get 100% accuracy. As such, future work emphasizing unsupervised learning will also require more fine-grained metrics, such as a dataset with hierarchical labels that appropriately distinguish specific instances (peach-can vs tomato-can), from general ones (cans or even just "cylindrical objects").
Results
| Experiment | Correct - 1st Epoch(%) | Correct - >1st Epoch (%) | Mean Objects per Graph | Mean Graphs per Object | Run Time (mins) | Episode Run Time (s) |
|---|---|---|---|---|---|---|
| surf_agent_unsupervised_10distinctobj | 80.00 | 98.89 | 1.22 | 1.1 | 24 | 14 |
| surf_agent_unsupervised_10distinctobj_noise | 80.00 | 85.56 | 1.08 | 1.44 | 40 | 24 |
| surf_agent_unsupervised_10simobj | 40.00 | 80.00 | 2.14 | 1.5 | 31 | 19 |
To obtain these results use print_unsupervised_stats(train_stats, epoch_len=10) (wandb logging is currently not written for unsupervised stats). Unsupervised, continual learning, by definition, cannot be parallelized across epochs. Therefore these experiments were run without multiprocessing (using run.py).
Unsupervised Inference
Most benchmark experiments assume a clean separation between objects, and a clearly defined episode structure — where each episode corresponds to a single object, and resets allow Monty to reinitialize its internal states. However, in real-world settings, such boundaries don't exist. Objects may be swapped, occluded, or even combined (e.g., a logo on a mug), and an agent must continuously perceive and adapt without external signals indicating when or whether an object has changed. This capability is essential for scaling to dynamic, real-world environments where compositionality, occlusion, and object transitions are the norm rather than the exception.
To simulate such a scenario, we designed an experimental setup that swaps the current object without resetting Monty's internal state. The goal is to test whether Monty can correctly abandon the old hypothesis and begin accumulating evidence on the new object — all without any explicit supervisory signal or internal reset. Unlike typical episodes where Monty’s internal state — including its learning modules, sensory modules, buffers, and hypothesis space — is reinitialized at object boundaries, here the model must dynamically adapt based solely on its stream of observations and internal evidence updates.
More specifically, these experiments are run purely in evaluation mode (i.e., pre-trained object graphs are loaded before the experiment begins) with no training or graph updates taking place. Monty stays in the matching phase, continuously updating its internal hypotheses based on sensory observations. For each object, the model performs a fixed number of matching steps before the object is swapped. At the end of each segment, we evaluate whether Monty’s most likely hypothesis correctly identifies the current object. All experiments are performed on 10 distinct objects from the YCB dataset and 10 random rotations for each object. Random noise is added to sensory observations.
Results
| Experiment | Correct (%) | Num Match Steps | Run Time (mins) | Episode Run Time (s) |
|---|---|---|---|---|
| unsupervised_inference_distinctobj_dist_agent | 97.00 | 97 | 12 | 5 |
| unsupervised_inference_distinctobj_surf_agent | 100.00 | 98 | 23 | 11 |
These experiments are currently run without multiprocessing (using run.py).
Compositional Datasets
Logos on Objects
The following experiments evaluate Monty's ability to learn and infer compositional objects, where these consist of simple 3D objects (a disk, a cube, a cylinder, a sphere, and a mug) with 2D logos on their surface. The logos are either the TBP logo or the Numenta logo. In the dataset, the logos can be in a standard orientation on the object, or oriented vertically. Finally, there is an instance of the mug with the TBP logo bent half-way along the logo at 45 degrees.
We want to determine the ability of a Monty system with a hierarchy of LMs (here, a single low-level LM sending input to a single high-level LM) to build compositional models of these kinds of objects. To enable learning such models, we provide some amount of supervision to the LMs. The low and high-level LMs begin by learning the 3D objects and logos in isolation, as standalone objects. These are referred to as object "parts" in the configs. We then present Monty the compositional objects, while the low-level LM is set to perform unsupervised inference. Any object IDs it detects to the high level LM. The high level LM continues learning, and is provided with a supervised label for the compositional object (e.g. 024_mug_tbp_horz).
To measure performance, we introduced two new metrics:
consistent_child_obj, which measures when a learning module detects an object within the set of plausible children objects. For example, the consistent child objects formug_tbp_horzwould bemugandtbp_logo. We use this since the lower level LM doesn't have the compositional model and we have no ability, e.g. a semantic sensor, to know which part it was sensing.mlh_prediction_error, which measures how closely the prediction of the most likely hypothesis matches the current input.
Results
| Experiment | Correct Child or Parent (%) | Used MLH (%) | Num Match Steps | Rotation Error (degrees) | Avg Prediction Error | Run Time (mins) |
|---|---|---|---|---|---|---|
| infer_comp_lvl1_with_monolithic_models | 89.29 | 84.52 | 415 | 56.28 | 0.25 | 34 |
| infer_comp_lvl1_with_comp_models | 86.90 | 23.81 | 32 | 40.58 | 0.31 | 4 |
| infer_comp_lvl2_with_comp_models | 84.29 | 31.43 | 38 | 44.59 | 0.31 | 11 |
| infer_comp_lvl3_with_comp_models | 63.43 | 46.57 | 35 | 47.58 | 0.31 | 15 |
These benchmarks are not currently expected to have good performance and are used to track our research progress for compositional datasets.
Note: To obtain these results, pretraining was run without parallelization across episodes, inference was run with parallelization.
You can download the data here:
Dataset Archive Format Download Link compositional_objects_1.1 tgz compositional_objects_1.1.tgz compositional_objects_1.1 zip compositional_objects_1.1.zip Unpack the archive in the
~/tbp/data/folder. For example:mkdir -p ~/tbp/data/ cd ~/tbp/data/ curl -L https://tbp-data-public-5e789bd48e75350c.s3.us-east-2.amazonaws.com/tbp.monty/compositional_objects_1.1.tgz | tar -xzf -mkdir -p ~/tbp/data/ cd ~/tbp/data/ curl -O https://tbp-data-public-5e789bd48e75350c.s3.us-east-2.amazonaws.com/tbp.monty/compositional_objects_1.1.zip unzip compositional_objects_1.1.zipTo generate the pretrained models, run the following experiments in order:
python run.py experiment=supervised_pre_training_flat_objects_wo_logos python run.py experiment=supervised_pre_training_logos_after_flat_objects python run.py experiment=supervised_pre_training_curved_objects_after_flat_and_logo python run.py experiment=supervised_pre_training_objects_with_logos_lvl1_monolithic_models python run.py experiment=supervised_pre_training_objects_with_logos_lvl1_comp_models python run.py experiment=supervised_pre_training_objects_with_logos_lvl1_comp_models_burst_sampling python run.py experiment=supervised_pre_training_objects_with_logos_lvl2_comp_models python run.py experiment=supervised_pre_training_objects_with_logos_lvl3_comp_models
Alternatively, you can download the pretrained models directly instead of running the pretraining experiments above:
Models Archive Format Download Link pretrained_compositional_objects_v3 tgz pretrained_compositional_objects_v3.tgz pretrained_compositional_objects_v3 zip pretrained_compositional_objects_v3.zip Unpack the archive in the
~/tbp/results/monty/pretrained_models/folder. For example:mkdir -p ~/tbp/results/monty/pretrained_models/ cd ~/tbp/results/monty/pretrained_models/ curl -L https://tbp-pretrained-models-public-c9c24aef2e49b897.s3.us-east-2.amazonaws.com/tbp.monty/pretrained_compositional_objects_v3.tgz | tar -xzf -mkdir -p ~/tbp/results/monty/pretrained_models/ cd ~/tbp/results/monty/pretrained_models/ curl -O https://tbp-pretrained-models-public-c9c24aef2e49b897.s3.us-east-2.amazonaws.com/tbp.monty/pretrained_compositional_objects_v3.zip unzip pretrained_compositional_objects_v3.zip
Monty-Meets-World
The following experiments evaluate a Monty model on real-world images derived from the RGBD camera of an iPad/iPhone device. The models that the Monty system leverages are based on photogrammetry scans of the same objects in the real world, and Monty learns on these in the simulated Habitat environment; this approach is taken because currently, we cannot track the movements of the iPad through space, and so Monty cannot leverage its typical sensorimotor learning to build the internal models.
For a really cool video of the first time Monty was tested in the real world, see the recording linked on our project showcase page.
These experiments have been designed to evaluate Monty's robustness to real-world data, and in this particular case, its ability to generalize from simulation to the real-world. In the world_image experiments, the model is evaluated on the aforementioned iPad extracted images, while in the randrot_noise_sim_on_scan_monty_world experiment, we evaluate the model in simulation at inference time, albeit with some noise added and with the distant agent fixed to a single location (i.e., no hypothesis-testing policy). This enables a reasonable evaluation of the sim-to-real change in performance. Furthermore, the world_image experiments are intended to capture a variety of possible adversarial settings.
The dataset itself consists of 12 objects, with some representing multiple instances of similar objects (e.g. the Numenta mug vs the terracotta mug, or the hot sauce bottle vs the cocktail bitters bottle). Each one of the world_image datasets contains 4 different views of each of these objects, for a total of 48 views for each dataset, or 240 views across all 5 real-world settings. The experimental conditions are i) standard (no adversarial modifications), ii) dark (low-lighting), iii) bright, iv) hand intrusion (a hand is significantly encircling and thereby occluding parts of the object), and v) multi-object (the first 2/4 images are the object paired with a similar object next to it, and the latter 2/4 images are the object paired with a structurally different object).
You can download the data:
| Dataset | Archive Format | Download Link |
|---|---|---|
| worldimages | tgz | worldimages.tgz |
| worldimages | zip | worldimages.zip |
Unpack the archive in the ~/tbp/data/ folder. For example:
mkdir -p ~/tbp/data/
cd ~/tbp/data/
curl -L https://tbp-data-public-5e789bd48e75350c.s3.us-east-2.amazonaws.com/tbp.monty/worldimages.tgz | tar -xzf -
mkdir -p ~/tbp/data/
cd ~/tbp/data/
curl -O https://tbp-data-public-5e789bd48e75350c.s3.us-east-2.amazonaws.com/tbp.monty/worldimages.zip
unzip worldimages.zip
Finally, note that the world_image experimental runs do not support running with multi-processing, so you cannot use the run_parallel.py script when running these. This is because an appropriate object_init_sampler has yet to be defined for this experimental setup. Note that this restriction does not apply to randrot_noise_sim_on_scan_monty_world, which can still be parallelized with run_parallel.py. All experiments are run with 16 CPUs for benchmarking purposes.
See the monty_lab project folder for the code.
The
randrot_noise_sim_on_scan_monty_worldexperiment requires HabitatSim to be installed as well as additional data containing the meshes for the simulator to use.You can download the data:
Dataset Archive Format Download Link numenta_lab tgz numenta_lab.tgz numenta_lab zip numenta_lab.zip Unpack the archive in the
~/tbp/data/folder. For example:mkdir -p ~/tbp/data/ cd ~/tbp/data/ curl -L https://tbp-data-public-5e789bd48e75350c.s3.us-east-2.amazonaws.com/tbp.monty/numenta_lab.tgz | tar -xzf -mkdir -p ~/tbp/data/ cd ~/tbp/data/ curl -O https://tbp-data-public-5e789bd48e75350c.s3.us-east-2.amazonaws.com/tbp.monty/numenta_lab.zip unzip numenta_lab.zip
Results
| Experiment | Correct (%) | Used MLH (%) | Num Match Steps | Run Time (mins) | Episode Run Time (s) |
|---|---|---|---|---|---|
| randrot_noise_sim_on_scan_monty_world | 88.33 | 90.00 | 456 | 22 | 165 |
| world_image_on_scanned_model | 68.75 | 68.75 | 403 | 10 | 12 |
| dark_world_image_on_scanned_model | 29.17 | 14.58 | 234 | 8 | 9 |
| bright_world_image_on_scanned_model | 37.50 | 62.50 | 400 | 10 | 11 |
| hand_intrusion_world_image_on_scanned_model | 37.50 | 27.08 | 277 | 10 | 11 |
| multi_object_world_image_on_scanned_model | 22.92 | 2.08 | 155 | 5 | 5 |
Rotation errors are excluded because they are meaningless, since no ground truth rotation is provided
Explanation of Some of the Results
- Why is there such a drop in performance going from sim-to-real?
Although there are likely a variety of factors at play, it is worth emphasizing that it is highly non trivial to learn on photogrammetry scanned objects, and then generalize to images extracted from an RGBD depth camera, as this is a significant shift in the source of data available to the model. Furthermore, note that due to structural similarity of several of the objects in the dataset to one another, it is not too surprising that the model may converge to an incorrect hypothesis given only a single view. - Why is the percent MLH used so high?
Each episode is restricted to a single viewing angle of an object, resulting in significant ambiguity. Furthermore, episodes use a maximum of 100 matching steps so that these experiments can be run quickly. - Are there any other factors contributing to performance differences to be aware of?
During the collection of some of the datasets, the "smoothing" setting was unfortunately not active; this affects the standard (world_image_on_scanned_model) dataset, as well as the bright and hand-intrusion experiments. Broadly, this appears to not have had too much of an impact, given that e.g., dark and bright perform comparably (with bright actually being better, even though it was acquired without smoothing). There appear to be a couple of images (around 5 out of the 240 images), where this has resulted in a large step-change in the depth reading, and as a result of this, the experiment begins with the model "off" the object, even though to a human eye, the initial position of the patch is clearly on the object. This will be addressed in a future update to the data-sets, where we can also implement any additional changes we may wish to make during data collection (e.g., more control of object poses, or the inclusion of motor data). - What steps should be noted when acquiring new images?
In addition to ensuring that the "smoothing" option is toggled on (currently off by default), lie the iPad on its side, ensuring that the volume bottom is at the top, so that the orientation of images are consistent across the data-sets. In general, objects should be as close to the camera as possible when taking images, while ensuring the depth values do not begin to clip.
Future Capabilities
In the future, we will expand this test suite to cover more capabilities such as more multiple object scenarios (touching vs. occluding objects), compositional objects, object categories, distorted objects, different features on the same morphology, objects in different states, object behaviors, and abstract concepts.
Help Us Make This Page Better
All our docs are open-source. If something is wrong or unclear, submit a PR to fix it!
Updated 2 days ago