Observations, Transforms & Sensor Modules
Transforms
Before sending information to the sensor module which extracts features and poses, we can apply transforms to the raw input. Possible transforms are listed in tables below. Transforms are applied to all sensors in an environment before sending observations to the SMs and are specified in the environment interface arguments.
| List of all transform classes | Description |
|---|---|
| MissingToMaxDepth | Habitat depth sensors return 0 when no mesh is present at a location. Instead, return max_depth. |
| AddNoiseToRawDepthImage | Add gaussian noise to raw sensory input. |
| DepthTo3DLocations | Transform semantic and depth observations from camera coordinates (2D) into agent (or world) coordinates (3D). Also estimates whether we are on the object or not if no semantic sensor is present. |
Sensor Modules
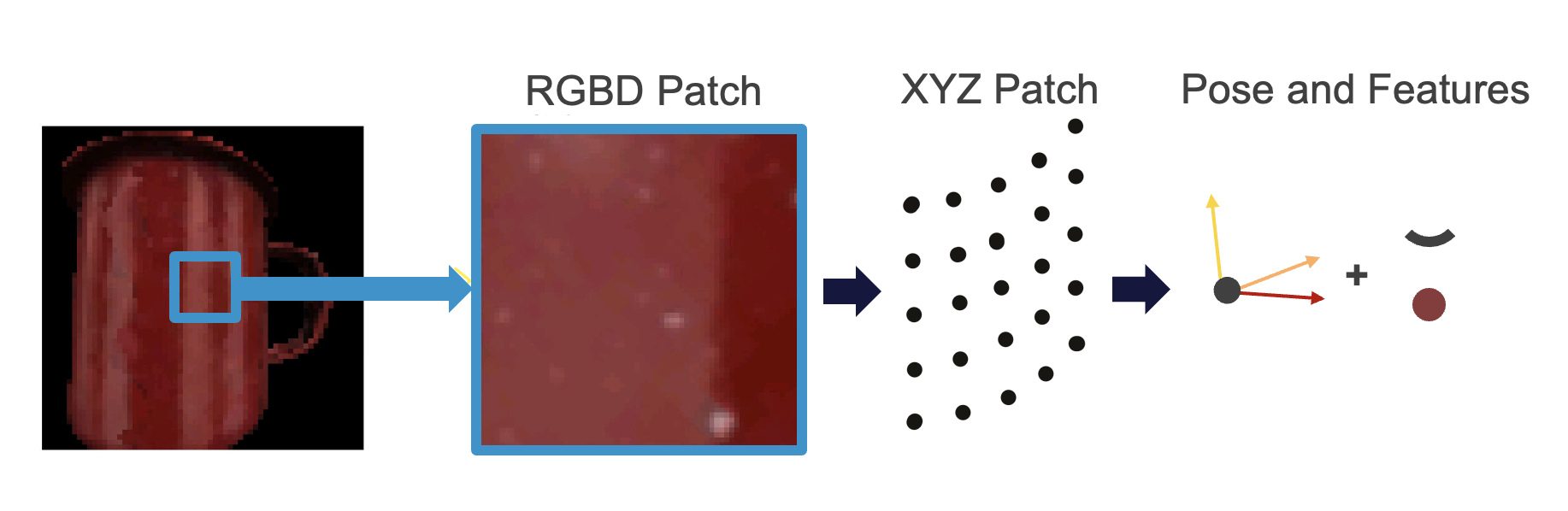
The transformed, raw input is then sent to the sensor module and turned into the CMP-compliant format. The universal format that all sensor modules output is features at pose in 3D space. Each sensor connects to a sensor module which turns the raw sensory input into this format of features at locations. Each input therefore contains x, y, z coordinates of the feature location relative to the body and three orthonormal vectors indicating its rotation. In sensor modules these pose-defining vectors are defined by the surface normal and principal curvature directions sensed at the center of the patch. In learning modules the pose vectors are defined by the detected object rotation. Additionally, the sensor module returns the sensed pose-independent features at this location (e.g. color, texture, curvature, ...). The sensed features can be modality-specific (e.g. color for vision or temperature for touch) while the pose is modality agnostic.
| List of all sensor module classes | Description |
|---|---|
| SensorModule | Abstract sensor module class. |
| CameraSM | Sensor module connected to an RGBD camera. Extracts pose and features in CMP format from an RGBD patch. Keeps track of agent and sensor states. Also checks if observation is on object and should be sent to LM. Can be configured to add feature noise. |
| Probe | A probe that can be inserted into Monty in place of a sensor module. It will track raw observations for logging, and can be used by experiments for positioning procedures, visualization, etc. What distinguishes a probe from a sensor module is that it does not process observations and does not emit a Cortical Message. |
Noise
Each sensor module accepts noise_params, which configure the DefaultMessageNoise that adds feature and location noise to the created Cortical Message before sending. Features and location noise can be configured individually.
Feature Change Filtering
Each sensor module accepts delta_thresholds, which configure a FeatureChangeFilter that may set the use_state message attribute to False if sensed features did not change significantly between subsequent observations. Significance is defined by the delta_thresholds parameter for each feature.
Transforms vs. Sensor Modules
For an overview of which type of data processing belongs where please refer to the following rules:
-
Any data transforms that apply to the entire dataset or to all SMs can be placed in the dataset.transform.
-
Any data transforms that are specific to a sensory modality belong in SM. For example, an auditory SM could include a preprocessing step that computes a spectrogram, followed by a convolutional neural network that outputs feature maps.
-
Transforming locations in space from coordinates relative to the sensor, to coordinates relative to the body, happens in the SM.
-
The output of both SMs and LMs is a Message class instance containing information about pose relative to the body and detected features at that pose. This is the input that any LM expects.
Features Extracted by the Sensor Module
In this implementation, some features are extracted using all of the information in the sensor patch (e.g. locations of all points in the patch for surface normal and curvature calculation) but then refer to the center of the patch (e.g. only the curvature and surface normal of the center are returned). At the moment all the feature extraction is predefined but in the future, one could also imagine some features being learned.
Surface Normals and Principle Curvatures
Each Sensor Module needs to extract a pose from the sensory input it receives. This pose can be defined by the surface normal and the two principal curvature vectors. These three vectors are orthogonal to each other, where the surface normal is the vector perpendicular to the surface and pointing away from the object, and the two principal curvature vectors point in the directions of the greatest and least curvature of the surface.
We can use the surface normal (previously referred to as point-normal) and principal curvature to define the orientation of the sensor patch. The following video describes what those represent.
CMP and the Message Class
The Cortical Messaging Protocol is defined in the Message class. The output of every SM and LM is an instance of the Message class which makes sure it contains all required information. The required information stored in a Message instance is:
-
location (relative to the body)
-
morphological features: pose_vectors (3x3 orthonormal), pose_fully_defined (bool), on_object (bool)
-
non-morphological features: color, texture, curvature, ... (dict)
-
confidence (in [0, 1])
-
use_state (bool)
-
sender_id (unique string identifying the sender)
-
sender_type (string in ["SM", "LM"])
The Message class is quite general and depending who outputs it, it can be interpreted in different ways. As output of the sensor module, it can be seen as a percept. When output by the learning module it can be interpreted as the hypothesized or most likely percept. When it is the motor output of the LM it can be seen as a goal (for instance specifying the desired location and orientation of a sensor or object in the world). Lastly, when sent as lateral votes between LMs we send a list of message class instances which are interpreted as votes (where votes do not contain non-morphological, modality-specific features but only pose information associated with object IDs).
Help Us Make This Page Better
All our docs are open-source. If something is wrong or unclear, submit a PR to fix it!
Updated about 1 month ago