Running Your First Experiment
Introduction
In this tutorial we will introduce the basic mechanics of Monty experiment configs, how to run them, and what happens during the execution of a Monty experiment. Since we will focus mainly on the execution of an experiment, we'll configure and run the simplest possible experiment and walk through it step-by-step. Please have a look at the next tutorials for more concrete examples of running the code with our current graph learning approach.
Don't have the YCB Dataset Downloaded?
Most of our tutorials require the YCB dataset, including this one. Please follow the instructions on downloading it here.
Setting up the Experiment Config
Below instructions assume you'll be running an experiment within the checked out
tbp.montyrepository. This is the recommended way to start. Once you are familiar with Monty, if you'd rather setup your experiment in your own repository, then take a look at Running An Experiment From A Different Repository.
Monty uses Hydra for configuration. The src/tbp/monty/conf directory serves as the root configuration directory, and experiment configs are located under src/tbp/monty/conf/experiment. The experiment config for this tutorial is located at src/tbp/monty/conf/experiment/tutorial/first_experiment.yaml which contains the following:
# @package _global_
# To test your environment and help you familiarize yourself with the code,
# we'll run the simplest possible experiment. We'll use a model with a single
# learning module as specified in /monty/learning_module. We'll also skip
# evaluation, train for a single epoch for a single step, and only train on a
# single object, as specified in /env_interface.
# The defaults below are the all the components of an experiment you must
# specify.
defaults:
# /monty defines what Monty we will use and how many exploration, evaluation,
# training, and total steps to configure it with.
- /monty: graph_exp1000_e3_t3_tot2500
# /monty/motor_system_config specifies what motor system and motor policy to
# use within Monty. We use a motor system with an InformedPolicyRandomWalk where
# movement rotations are 5 degrees.
- /monty/motor_system_config: informed_random_walk_5
# /monty/learning_module is Monty's learning module configuration. We use a
# single DisplacementGraphLM learning module.
- /monty/learning_module: displacement_1lm
# /monty/sensor_module is Monty's sensor module configuration. We use a sensor
# module that handles input from a camera.
- /monty/sensor_module: camera_dist
# /monty/connectivity is the connectivity between the learning modules and
# the sensor modules. We connect one sensor module with one learning module.
- /monty/connectivity: 1lm_1sm
# /environment specifies the environment configuration to use. We use a
# Habitat simulator environment, loaded with the YCB dataset, and Monty
# controls a "distant" agent. Distant agent is like an eye, looking at things
# from a distance.
- /environment: habitat_ycb_dist_agent_semantics0
# /env_interface specifies how to setup the enviromment for the experiment.
# We will train on one object and use a predefined rotation for placement of
# one object.
- /env_interface: tutorial_train_1obj_predefined
# /env_interface/positioning_procedures specifies the positioning procedures
# that the experiment will run before each episode. A positioning procedure is
# analogous to an experimenter manually moving the subject into initial
# experimental position, e.g., placing an animal in front of a screen.
- /env_interface/positioning_procedures_train: getgoodview_viewfinder_patch
# /env_interface/transform specifies the transform pipeline to use to process
# environment observations before sending them to Monty.
- /env_interface/transform: missing_depthto3d_sensor2_semantic0
# /logging specifies the logging configuration to use. We tell Monty to use
# the SILENT data logging mode, Python to use the WARNING log level, and we
# output the data logs and python logs where training models are saved.
- /logging: silent_warning_train
experiment:
# The top-level _target_ is what kind of experiment we want to run.
_target_: tbp.monty.frameworks.experiments.pretraining_experiments.MontySupervisedObjectPretrainingExperiment
# config specifies the configuration of the experiment itself.
config:
# `show_sensor_output: true` will display a live plot of the sensor output.
show_sensor_output: false
# The maximum number of steps to train for.
max_train_steps: 1
# The maximum number of steps to evaluate for.
max_eval_steps: 500
# The maximum number of steps to run for.
max_total_steps: 6000
# The number of epochs to train for.
n_train_epochs: 1
# The number of epochs to evaluate for.
n_eval_epochs: 3
# The path to the model to load, if any.
model_name_or_path: ""
min_lms_match: 1
# The random seed for the experiment.
seed: 42
# The list of learning module IDs to supervise, or "all" to supervise all
# learning modules.
supervised_lm_ids: all
logging:
# Every experiment has a unique run name. This is used to identify the
# experiment in the logs and to save a trained model.
run_name: first_experiment
Running the Experiment
Monty experiments are run with run.py (or run_parallel.py) located directly under tbp.monty. To run the experiment defined above, cd into tbp.monty, make sure the tbp.monty environment has been activated (via conda activate tbp.monty), and enter
python run.py experiment=tutorial/first_experiment
The experiment argument is determined by the location of the experiment config, relative to the src/tbp/monty/conf/experiment directory. This experiment is named tutorial/first_experiment since the config is located at src/tbp/monty/conf/experiment/tutorial/first_experiment.yaml.
What Just Happened?
Now that you have run your first experiment, let's unpack what happened. This first section involves a lot of text, but rest assured, once you grok this first experiment, the rest of the tutorials will be much more interactive and will focus on running experiments and using tooling. This first experiment is virtually the simplest one possible, but it is designed to familiarize you with all the pieces and parts of the experimental workflow to give you a good foundation for further experimentation.
Experiments are implemented as Python classes with a run method. In essence, run.py creates an experiment from a config and calls the experiment's run method. Notice that first_experiment has do_eval set to false, so the experiment will only do training.
Experiment Structure: Epochs, Episodes, and Steps
One epoch will run training (or evaluation) on all the specified objects. An epoch generally consists of multiple episodes, one for each object, or for each pose of an object in the environment. An episode is one training or evaluating session with one single object. This episode consists of a sequence of steps.
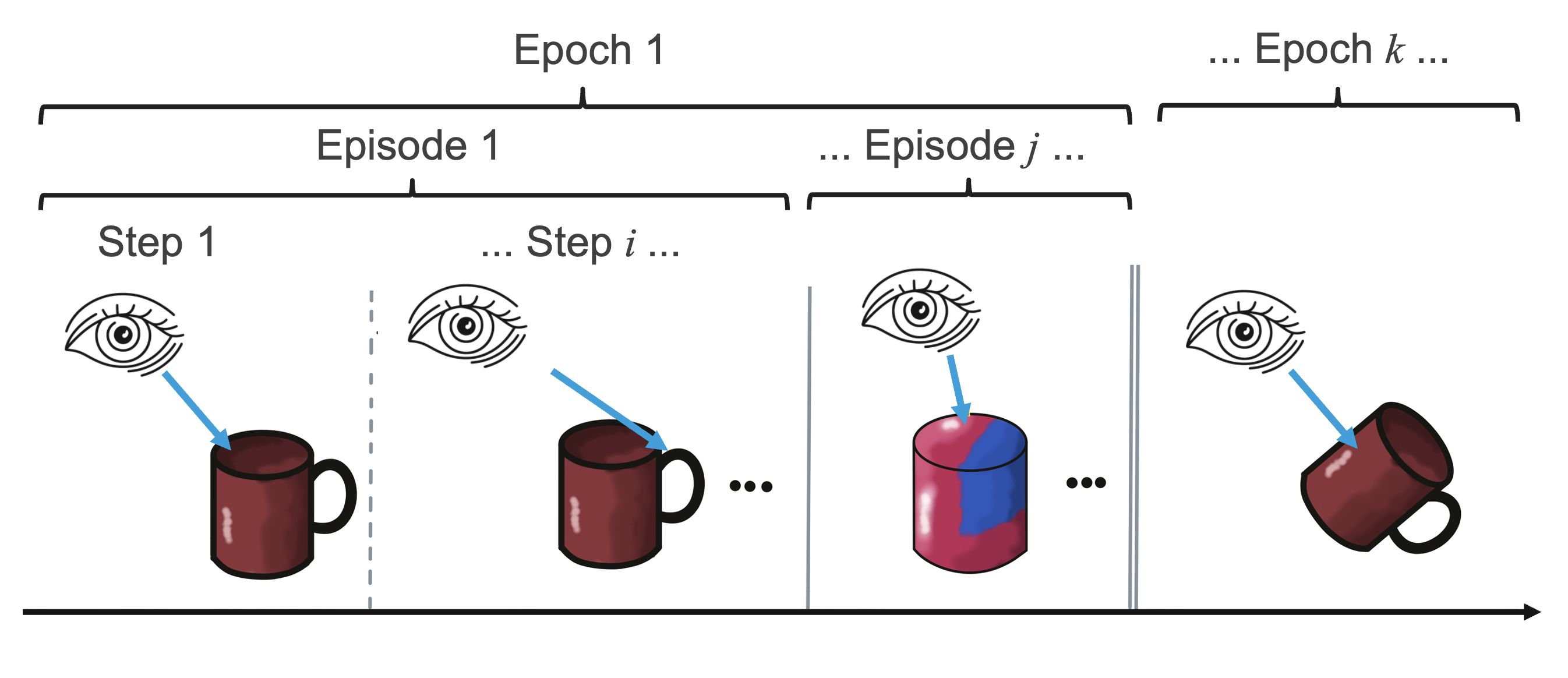
What happens in a step depends on the particular experiment, but an example would be: shifting the agent's position, reading sensor inputs, transforming sensor inputs to features, and adding these features to an object model. For more details on this default experiment setup see the experiment description in the How Monty Works section.
If you examine the MontyExperiment class, the parent class of MontySupervisedObjectPretrainingExperiment, you will notice that there are related methods like {pre,post}_epoch, and {pre,post}_episode. With inheritance or mixin classes, you can use these methods to customize what happens before during and after each epoch, or episode. For example, MontySupervisedObjectPretrainingExperiment reimplements pre_episode and post_epoch to provide extra functionality specific to pretraining experiments. Also notice that each method contains calls to a logger. Logger classes can also be customized to log specific information at each control point. Finally, we save a model with the save_state_dict method at the end of each epoch. All told, the sequence of method calls goes something like
MontyExperiment.runMontyExperiment.train(loops over epochs)- Do pre-train logging.
MontyExperiment.run_epoch(loops over episodes)MontyExperiment.pre_epoch- Do pre-epoch logging.
MontyExperiment.run_episode(loops over steps)MontyExperiment.pre_episode- Do pre-episode logging.
Monty.stepMontyExperiment.post_episode- Update object model in memory.
- Do post-episode logging
MontyExperiment.post_epochMontyExperiment.save_state_dict.- Do post-epoch logging.
- Do post-train logging.
and this is exactly the procedure that was executed when you ran python run.py experiment=tutorial/first_experiment. (Please note that we're writing MontyExperiment in the above sequence rather than MontySupervisedObjectPretrainingExperiment for the sake of generality). When we run Monty in evaluation mode, MontyExperiment.run calls MontyExperiment.evaluate, resulting in the same sequence of calls minus the model updating step in MontyExperiment.post_episode. See the experiment description in the How Monty Works section for more details on epochs, episodes, and steps.
Model
The model is specified in the /monty section of defaults. In the case it is the graph_exp1000_e3_t3_tot2500 model, which in a MontyForGraphMatching model with 1 000 exploratory steps, 3 minimum eval steps, 3 minimum train steps, and 2 500 maximum total steps.
# @package experiment.config.monty_config
monty_class: ${monty.class:tbp.monty.frameworks.models.graph_matching.MontyForGraphMatching}
monty_args:
num_exploratory_steps: 1000
min_eval_steps: 3
min_train_steps: 3
max_total_steps: 2500
The model requires additional configuration in form of the motor system, learning modules, sensor modules, and the overall connectivity. These are specified respectively in the /monty/motor_system_config, /monty/learning_module, /monty/sensor_module, and /monty/connectivity sections of defaults. For more details on configuring custom learning or sensor modules see this guide.
For now, we will start with one of the simpler and most common versions of this complex system. Our first model has one Learning Module (LM) and two Sensor Modules (SMs). Why two SMs and only one LM? One SM provides the LM with processed observations, while the second SM serves as our experimental probe and is used solely to initialize the agent at the beginning of the experiment.
Note that in our /monty/connectivity: 1lm_1sm the sm_to_agent_dict field of the model config maps each SM to an "agent" (i.e. a moveable part), and only a single agent is specified, meaning that our model has one moveable part with one sensor attached to it. In particular, it has an RGBD camera attached to it.
Environment
The environment is specified in the /environment section of defaults. In this case, we are using a Habitat simulator environment, loaded with the YCB dataset, where Monty controls a "distant" agent.
Steps
By now, we know that an experiment starts with the run method calling train and evaluate methods, that each of these runs one or more epochs, which consists of one or more episodes, and finally each episode repeatedly calls model.step. Now we will start unpacking each of these levels, starting with the innermost loop over steps.
As mentioned previously, in /monty: graph_exp1000_e3_t3_tot2500, notice that the model class is specified as ${monty.class:tbp.monty.frameworks.models.graph_matching.MontyForGraphMatching} (it uses the monty.class resolver that passes the Python class itself to the config), which is a subclass of tbp.monty.frameworks.models.monty_base.MontyBase, which in turn is a subclass of tbp.monty.frameworks.models.abstract_monty_classes.Monty. In the abstract base class Monty, you will see that there are two template methods for two types of steps: _exploratory_step and _matching_step. In turn, each of these steps is defined as a sequence of calls to other abstract methods, including _set_step_type_and_check_if_done, which is a point at which the step type can be switched. The conceptual difference between these types of steps is that during exploratory steps, no inference is attempted, which means no voting and no keeping track of which objects or poses are possible matches to the current observation. Each time model.step is called in the experimental procedure listed under the "Episodes and Epochs" heading, either _exploratory_step or _matching_step will be called. In a typical experiment, training consists of running _matching_step until a) an object is recognized, or b) all known objects are ruled out, or c) a step counter exceeds a threshold. Regardless of how matching-steps is terminated, the system then switches to running exploratory step so as to gather more observations and build a more complete model of an object.
You can, of course, customize step types and when to switch between step types by defining subclasses or mixins. To set the initial step type, use model.pre_episode. To adjust when and how to switch step types, use _set_step_type_and_check_if_done.
In this particular experiment, n_train_epochs was set to 1, and max_train_steps was set to 1. This means a single epoch was run, with one matching step per episode. In the next section, we go up a level from the model step to understand episodes and epochs.
Environment Interface
We now turn our attention to how the experiment controls the environment and the agent, which happens via what we call an environment interface.
The environment interface class is the way we interact with a simulation environment. The objects within an environment are assumed to be the same for both training and evaluation (for now). Note, however, that object orientations, as well as specific observations obtained from an object, will generally differ across training and evaluation.
The environment interface is basically how the experiment controls the environment during a running experiment. Its job is to initialize, reset, and setup the environment for each epoch and episode, pass actions from the model to the environment, and return observations from the environment to the model. Note that the next observation is decided by the last action, and the actions are selected by a motor_system. By changing the actions, the model controls what it observes next, just as you would expect from a sensorimotor system.
Now, finally answering our question of what happens in an episode, notice that our config uses a special type of environment interface: OneObjectPerEpisodeInterface (note that this is a subclass of Interface which is kept as general as possible to allow for flexible subclass customization). As indicated in the docstring, this environment interface has a list of objects, and at the beginning / end of an episode, it removes the current object from the environment, increments a (cyclical) counter that determines which object is next, and places the new object in the environment. The arguments to OneObjectPerEpisodeInterface determine which objects are added to the environment and in what pose. In our config, we use a single list with one YCB object, a mug.
Final Notes on the Model
To wrap up this tutorial, we'll cover a few more details of the model. Recall that sm_to_agent_dict assigns each SM to a moveable part (i.e. an "agent"). The action space for each moveable part is in turn defined in the motor_system_config part of the model config. Once an action is executed, the agent moves, and each sensor attached to that agent (here just a single RGBD sensor) receives an observation. Just as sm_to_agent_dict specifies which sensors are attached to which agents, in /monty/connectivity: 1lm_1sm the field sm_to_lm_matrix specifies for each LM which SMs it will receive observations from. Thus, observations flow from agents to sensor modules (SMs), and from SMs to learning modules (LMs), where all actual modeling takes place in the LM. Near the end of model.step (remember, this can be either matching_step or exploratory_step), the model selects actions and closes the loop between the model and the environment. Finally, at the end of each epoch, we save a model in a directory specified by the config.logging.output_dir configuration field (pre-defined in /logging: silent_warning_train in our config).
Summary
That was a lot of text, so let's review what all went into this experiment.
- We ran a
MontyExperimentusingrun.py - We went through the
trainprocedure with one epoch - The epoch looped over a list of objects of length 1 - so a single episode was run
- The max steps was set to 1, so all told, we took one single step on one single object
- Our model had a single agent with a single RGBD camera attached to it
- During
model.step,matching_stepwas called and one SM received one observation from the environment - The model selected the next action
- We saved our model at the end of the epoch
Congratulations on completing your first experiment! Ready to take the next step? Learn the ins-and-outs of pretraining a model.
Help Us Make This Page Better
All our docs are open-source. If something is wrong or unclear, submit a PR to fix it!
Updated 17 days ago