Experiment
During an experiment in the Monty framework an agent is collecting a sequence of observations by interacting with an environment. We distinguish between training (internal models are being updated using this sequence of observations) and evaluation (the agent only performs inference using already learned models but does not update them). The MontyExperiment class implements and coordinates this training and evaluation of Monty models.
Step Types and Discretizing Time
In reality an agent interacts continuously with the world and time is not explicitly discretized. For easier implementation we use steps as the smallest increment of time. Additionally, we divide an experiment into multiple episodes and epochs for easier measurement of performance. Overall, we discretize time in the three ways listed below.
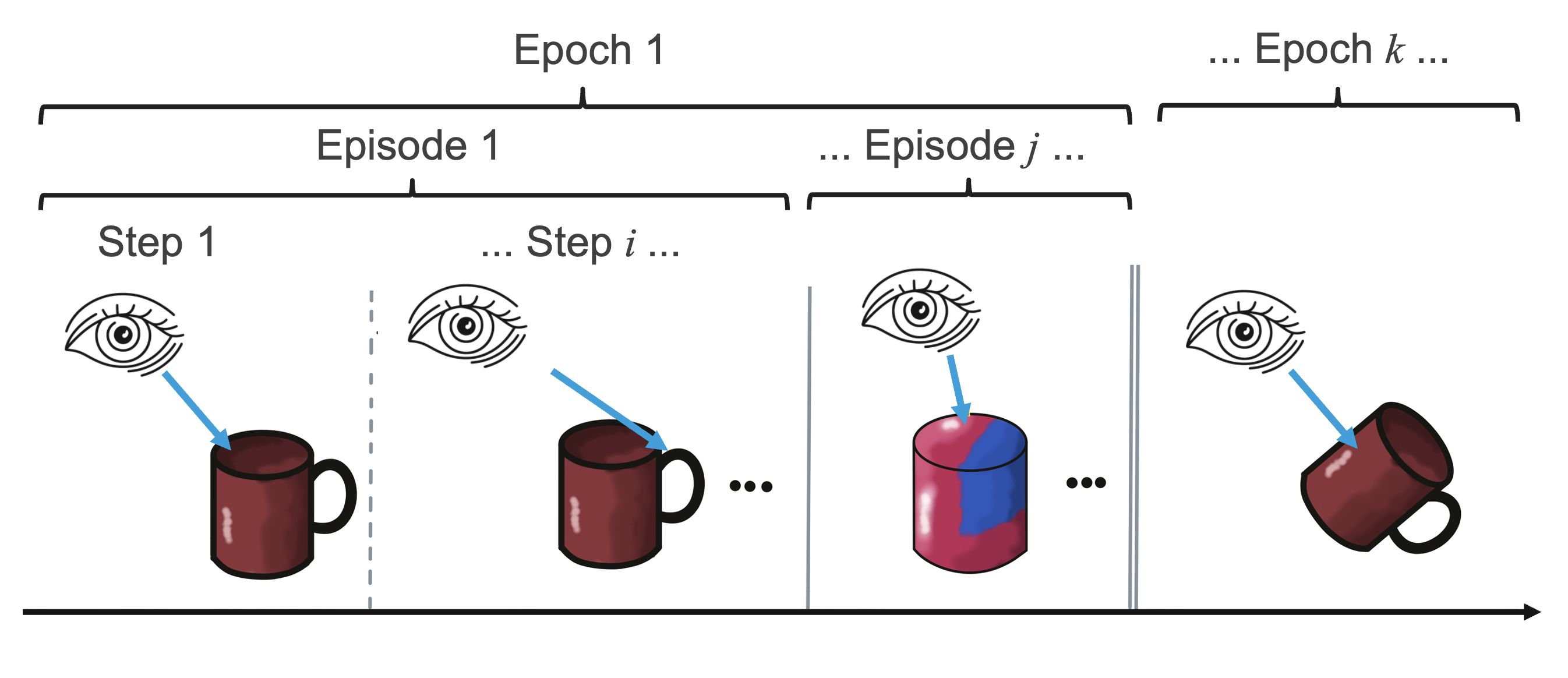
-
Step: taking zero, one, or more actions and receiving one observation. There are different types of steps that track more specifically whether learning module updates were performed either individually for each LM or more globally for the Monty class.
-
monty_step (model.episode_steps total_steps): number of observations sent to the Monty model. This includes observations that were not interesting enough to be sent to an LM such as off-object observations. It includes both matching and exploratory steps.
-
monty_matching_step (
model.matching_steps): At least one LM performed a matching step (updating its possible matches using an observation). There are also exploratory steps which do not update possible matches and only store an observation in the LMs buffer. These are not counted here. -
num_steps (
lm.buffer.get_num_matching_steps): Number of matching steps that a specific LM performed. -
lm_step (
max(num_steps)): Number of matching steps performed by the LM that took the most steps. -
lm_steps_indv_ts (
lm.buffer["individual_ts_reached_at_step"]): Number of matching steps a specific LM performed until reaching a local terminal state. A local terminal state means that a specific LM has settled on a result (match or no match). This does not mean that the entire Monty system has reached a terminal state since it usually requires multiple LMs to have reached a local terminal state. For more details see section Terminal Condition
-
-
Episode: putting a single object in the environment and taking steps until a terminal condition is reached, like recognizing the object or exceeding max steps.
-
Epoch: running one episode on each object in the training or eval set of objects.
In the long term, we might remove the episode and epoch chunking and simply have the agent continuously interact with a given environment without resetting it. Removing the step discretization of time will probably not be possible (maybe with neuromorphic hardware?) but we can simulate continuous time by making the step increments tiny and utilizing the different step types (like only sending an observation to the LM if a significant feature change was detected).
Different Phases of Learning
The learning module is designed to be able to learn objects unsupervised, from scratch. This means it is not assumed that we start with any previous knowledge or even complete objects stored in memory (even though there is an option to load pre-trained models for faster testing). This means that the models in graph memory are updated after every episode and learning and inference are tightly intertwined. If an object was recognized, the model of this object is updated with new points. If no object was recognized, a new model is generated and stored in memory. This also means that the whole learning procedure is unsupervised as there are no object labels provided [1].
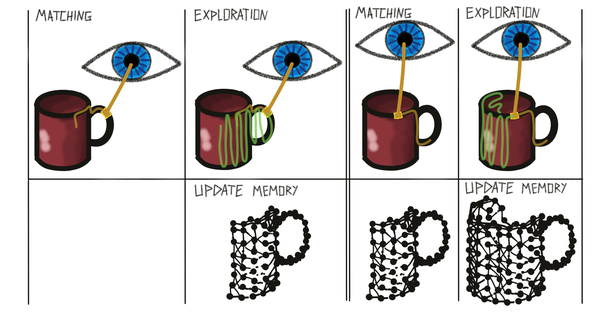
To keep track of which objects were used for building a graph (since we do not provide object labels in this unsupervised learning setup) we store two lists in each learning module: target_to_graph_id and graph_id_to_target. target_to_graph_id maps each graph to the set of objects that were used to build this graph. graph_id_to_target maps each object to the set of graphs that contain observations from it. These lists can later be used for analysis and to determine the performance of the system but they are not used for learning. This means learning can happen completely unsupervised, without any labels being provided.
There are two modes the learning module could be in: training and evaluation. They are both very similar as both use the same procedure of moving and narrowing down the list of possible objects and poses. The only difference between the two is that in the training mode the models in graph memory are updated after every episode. In practice, we currently often load pre-trained models into the graph memory and then only evaluate these. This avoids computation to first learn all objects before every evaluation and makes it easier to test on complete, error-free object models. However, it is important to keep in mind that anything that happens during evaluation also happens during training and that these two modes are almost identical. Save for practical reasons (to save computational time) we would never have to run evaluation as we perform the same operations during training as well. Just as in real life, we want to think of systems as always learning and improving and never reaching a point where they only perform inference.
The training mode is split into two phases that alternate: The matching phase and the exploration phase. During the matching phase the module tries to determine the object ID and pose from a series of observations and actions. This is the same as in evaluation. After a terminal condition is met (object recognized or no possible match found) the module goes into the exploration phase. This phase continues to collect observations and adds them into the buffer the same way as during the previous phase, only the matching step is skipped. The exploration phase is used to add more information to the graph memory at the end of an episode. For example, the matching procedure could be done after three steps telling us that the past three observations are not consistent with any models in memory. Therefore we would want to store a new graph in memory but a graph made of only three observations is not very useful. Hence, we keep moving for num_exploratory_steps to collect more information about this object before adding it to memory. This is not necessary during evaluation since we do not update our models then.
Experiment Classes
| List of all experiment classes | Description |
|---|---|
| MontyExperiment | Abstract experiment class from which all other experiment classes inherit. The experiment class handles the initialization of all Monty components. It also takes care of logging and the highest level calls to train, evaluate, pre_epoch, run_epoch, post_epoch, pre_episode, run_episode, post_episode, pre_step, and post_step. |
| MontyObjectRecognitionExperiment | Experiment class to test object recognition. The current default class for Habitat experiments. Saves the target object and pose for logging. Also contains some custom terminal condition checking and online plotting. |
| MontyGeneralizationExperiment | Same as previous but removes the current target object from the memory of all LMs. Can be used to test generalization to new objects. |
| MontySupervisedObjectPretrainingExperiment | Here we provide the object and pose of the target to the model. This way we can make sure we learn exactly one graph per object in the dataset and use the correct pose when merging graphs. This class is used for model pre-training. |
| ProfileExperimentMixin | Can be added to any experiment class to add a profiler. |
Help Us Make This Page Better
All our docs are open-source. If something is wrong or unclear, submit a PR to fix it!
Updated 2 months ago